Skeleton-based Action Recognition Models¶
AGCN¶
Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition
Abstract¶
In skeleton-based action recognition, graph convolutional networks (GCNs), which model the human body skeletons as spatiotemporal graphs, have achieved remarkable performance. However, in existing GCN-based methods, the topology of the graph is set manually, and it is fixed over all layers and input samples. This may not be optimal for the hierarchical GCN and diverse samples in action recognition tasks. In addition, the second-order information (the lengths and directions of bones) of the skeleton data, which is naturally more informative and discriminative for action recognition, is rarely investigated in existing methods. In this work, we propose a novel two-stream adaptive graph convolutional network (2s-AGCN) for skeleton-based action recognition. The topology of the graph in our model can be either uniformly or individually learned by the BP algorithm in an end-to-end manner. This data-driven method increases the flexibility of the model for graph construction and brings more generality to adapt to various data samples. Moreover, a two-stream framework is proposed to model both the first-order and the second-order information simultaneously, which shows notable improvement for the recognition accuracy. Extensive experiments on the two large-scale datasets, NTU-RGBD and Kinetics-Skeleton, demonstrate that the performance of our model exceeds the state-of-the-art with a significant margin.
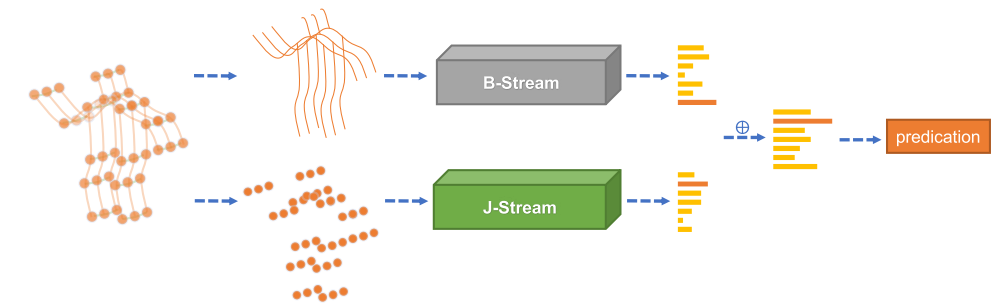
Results and Models¶
NTU60_XSub_2D¶
| frame sampling strategy | modality | gpus | backbone | top1 acc | testing protocol | FLOPs | params | config | ckpt | log |
|---|---|---|---|---|---|---|---|---|---|---|
| uniform 100 | joint | 8 | AGCN | 88.60 | 10 clips | 4.4G | 3.5M | config | ckpt | log |
| uniform 100 | bone | 8 | AGCN | 91.59 | 10 clips | 4.4G | 3.5M | config | ckpt | log |
| uniform 100 | joint-motion | 8 | AGCN | 88.02 | 10 clips | 4.4G | 3.5M | config | ckpt | log |
| uniform 100 | bone-motion | 8 | AGCN | 88.82 | 10 clips | 4.4G | 3.5M | config | ckpt | log |
| two-stream | 91.95 | |||||||||
| four-stream | 92.34 |
NTU60_XSub_3D¶
| frame sampling strategy | modality | gpus | backbone | top1 acc | testing protocol | FLOPs | params | config | ckpt | log |
|---|---|---|---|---|---|---|---|---|---|---|
| uniform 100 | joint | 8 | AGCN | 88.26 | 10 clips | 6.5G | 3.5M | config | ckpt | log |
| uniform 100 | bone | 8 | AGCN | 89.22 | 10 clips | 6.5G | 3.5M | config | ckpt | log |
| uniform 100 | joint-motion | 8 | AGCN | 86.73 | 10 clips | 6.5G | 3.5M | config | ckpt | log |
| uniform 100 | bone-motion | 8 | AGCN | 86.41 | 10 clips | 6.5G | 3.5M | config | ckpt | log |
| two-stream | 90.27 | |||||||||
| four-stream | 90.89 |
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size, and the original batch size.For two-stream fusion, we use joint : bone = 1 : 1. For four-stream fusion, we use joint : joint-motion : bone : bone-motion = 2 : 1 : 2 : 1. For more details about multi-stream fusion, please refer to this tutorial.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train STGCN model on NTU60-2D dataset in a deterministic option with periodic validation.
python tools/train.py configs/skeleton/2s-agcn/2s-agcn_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py \
--seed 0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test AGCN model on NTU60-2D dataset and dump the result to a pickle file.
python tools/test.py configs/skeleton/2s-agcn/2s-agcn_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{shi2019two,
title={Two-stream adaptive graph convolutional networks for skeleton-based action recognition},
author={Shi, Lei and Zhang, Yifan and Cheng, Jian and Lu, Hanqing},
booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
pages={12026--12035},
year={2019}
}
PoseC3D¶
Revisiting Skeleton-based Action Recognition
Abstract¶
Human skeleton, as a compact representation of human action, has received increasing attention in recent years. Many skeleton-based action recognition methods adopt graph convolutional networks (GCN) to extract features on top of human skeletons. Despite the positive results shown in previous works, GCN-based methods are subject to limitations in robustness, interoperability, and scalability. In this work, we propose PoseC3D, a new approach to skeleton-based action recognition, which relies on a 3D heatmap stack instead of a graph sequence as the base representation of human skeletons. Compared to GCN-based methods, PoseC3D is more effective in learning spatiotemporal features, more robust against pose estimation noises, and generalizes better in cross-dataset settings. Also, PoseC3D can handle multiple-person scenarios without additional computation cost, and its features can be easily integrated with other modalities at early fusion stages, which provides a great design space to further boost the performance. On four challenging datasets, PoseC3D consistently obtains superior performance, when used alone on skeletons and in combination with the RGB modality.

|
Pose Estimation Results


|
Keypoint Heatmap Volume Visualization


|
Limb Heatmap Volume Visualization


|
Results and Models¶
FineGYM¶
| frame sampling strategy | pseudo heatmap | gpus | backbone | Mean Top-1 | testing protocol | FLOPs | params | config | ckpt | log |
|---|---|---|---|---|---|---|---|---|---|---|
| uniform 48 | keypoint | 8 | SlowOnly-R50 | 93.5 | 10 clips | 20.6G | 2.0M | config | ckpt | log |
| uniform 48 | limb | 8 | SlowOnly-R50 | 93.6 | 10 clips | 20.6G | 2.0M | config | ckpt | log |
NTU60_XSub¶
| frame sampling strategy | pseudo heatmap | gpus | backbone | top1 acc | testing protocol | FLOPs | params | config | ckpt | log |
|---|---|---|---|---|---|---|---|---|---|---|
| uniform 48 | keypoint | 8 | SlowOnly-R50 | 93.6 | 10 clips | 20.6G | 2.0M | config | ckpt | log |
| uniform 48 | limb | 8 | SlowOnly-R50 | 93.5 | 10 clips | 20.6G | 2.0M | config | ckpt | log |
| Fusion | 94.0 |
UCF101¶
| frame sampling strategy | pseudo heatmap | gpus | backbone | top1 acc | testing protocol | FLOPs | params | config | ckpt | log |
|---|---|---|---|---|---|---|---|---|---|---|
| uniform 48 | keypoint | 8 | SlowOnly-R50 | 86.8 | 10 clips | 14.6G | 3.1M | config | ckpt | log |
HMDB51¶
| frame sampling strategy | pseudo heatmap | gpus | backbone | top1 acc | testing protocol | FLOPs | params | config | ckpt | log |
|---|---|---|---|---|---|---|---|---|---|---|
| uniform 48 | keypoint | 8 | SlowOnly-R50 | 69.6 | 10 clips | 14.6G | 3.0M | config | ckpt | log |
Kinetics400¶
| frame sampling strategy | pseudo heatmap | gpus | backbone | top1 acc | testing protocol | FLOPs | params | config | ckpt | log |
|---|---|---|---|---|---|---|---|---|---|---|
| uniform 48 | keypoint | 8 | SlowOnly-R50 | 47.4 | 10 clips | 19.1G | 3.2M | config | ckpt | log |
You can follow the guide in Preparing Skeleton Dataset to obtain skeleton annotations used in the above configs.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train PoseC3D model on FineGYM dataset in a deterministic option.
python tools/train.py configs/skeleton/posec3d/slowonly_r50_8xb16-u48-240e_gym-keypoint.py \
--seed=0 --deterministic
For training with your custom dataset, you can refer to Custom Dataset Training.
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test PoseC3D model on FineGYM dataset.
python tools/test.py configs/skeleton/posec3d/slowonly_r50_8xb16-u48-240e_gym-keypoint.py \
checkpoints/SOME_CHECKPOINT.pth
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@misc{duan2021revisiting,
title={Revisiting Skeleton-based Action Recognition},
author={Haodong Duan and Yue Zhao and Kai Chen and Dian Shao and Dahua Lin and Bo Dai},
year={2021},
eprint={2104.13586},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
STGCN¶
Spatial temporal graph convolutional networks for skeleton-based action recognition
Abstract¶
Dynamics of human body skeletons convey significant information for human action recognition. Conventional approaches for modeling skeletons usually rely on hand-crafted parts or traversal rules, thus resulting in limited expressive power and difficulties of generalization. In this work, we propose a novel model of dynamic skeletons called Spatial-Temporal Graph Convolutional Networks (ST-GCN), which moves beyond the limitations of previous methods by automatically learning both the spatial and temporal patterns from data. This formulation not only leads to greater expressive power but also stronger generalization capability. On two large datasets, Kinetics and NTU-RGBD, it achieves substantial improvements over mainstream methods.
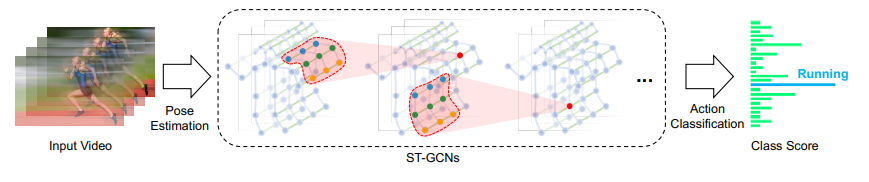
Results and Models¶
NTU60_XSub_2D¶
| frame sampling strategy | modality | gpus | backbone | top1 acc | testing protocol | FLOPs | params | config | ckpt | log |
|---|---|---|---|---|---|---|---|---|---|---|
| uniform 100 | joint | 8 | STGCN | 88.95 | 10 clips | 3.8G | 3.1M | config | ckpt | log |
| uniform 100 | bone | 8 | STGCN | 91.69 | 10 clips | 3.8G | 3.1M | config | ckpt | log |
| uniform 100 | joint-motion | 8 | STGCN | 86.90 | 10 clips | 3.8G | 3.1M | config | ckpt | log |
| uniform 100 | bone-motion | 8 | STGCN | 87.86 | 10 clips | 3.8G | 3.1M | config | ckpt | log |
| two-stream | 92.12 | |||||||||
| four-stream | 92.34 |
NTU60_XSub_3D¶
| frame sampling strategy | modality | gpus | backbone | top1 acc | testing protocol | FLOPs | params | config | ckpt | log |
|---|---|---|---|---|---|---|---|---|---|---|
| uniform 100 | joint | 8 | STGCN | 88.11 | 10 clips | 5.7G | 3.1M | config | ckpt | log |
| uniform 100 | bone | 8 | STGCN | 88.76 | 10 clips | 5.7G | 3.1M | config | ckpt | log |
| uniform 100 | joint-motion | 8 | STGCN | 86.06 | 10 clips | 5.7G | 3.1M | config | ckpt | log |
| uniform 100 | bone-motion | 8 | STGCN | 85.49 | 10 clips | 5.7G | 3.1M | config | ckpt | log |
| two-stream | 90.14 | |||||||||
| four-stream | 90.39 |
NTU120_XSub_2D¶
| frame sampling strategy | modality | gpus | backbone | top1 acc | testing protocol | FLOPs | params | config | ckpt | log |
|---|---|---|---|---|---|---|---|---|---|---|
| uniform 100 | joint | 8 | STGCN | 83.19 | 10 clips | 3.8G | 3.1M | config | ckpt | log |
| uniform 100 | bone | 8 | STGCN | 83.36 | 10 clips | 3.8G | 3.1M | config | ckpt | log |
| uniform 100 | joint-motion | 8 | STGCN | 78.87 | 10 clips | 3.8G | 3.1M | config | ckpt | log |
| uniform 100 | bone-motion | 8 | STGCN | 79.55 | 10 clips | 3.8G | 3.1M | config | ckpt | log |
| two-stream | 84.84 | |||||||||
| four-stream | 85.23 |
NTU120_XSub_3D¶
| frame sampling strategy | modality | gpus | backbone | top1 acc | testing protocol | FLOPs | params | config | ckpt | log |
|---|---|---|---|---|---|---|---|---|---|---|
| uniform 100 | joint | 8 | STGCN | 82.15 | 10 clips | 5.7G | 3.1M | config | ckpt | log |
| uniform 100 | bone | 8 | STGCN | 84.28 | 10 clips | 5.7G | 3.1M | config | ckpt | log |
| uniform 100 | joint-motion | 8 | STGCN | 78.93 | 10 clips | 5.7G | 3.1M | config | ckpt | log |
| uniform 100 | bone-motion | 8 | STGCN | 80.02 | 10 clips | 5.7G | 3.1M | config | ckpt | log |
| two-stream | 85.68 | |||||||||
| four-stream | 86.19 |
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size, and the original batch size.For two-stream fusion, we use joint : bone = 1 : 1. For four-stream fusion, we use joint : joint-motion : bone : bone-motion = 2 : 1 : 2 : 1. For more details about multi-stream fusion, please refer to this tutorial.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train STGCN model on NTU60-2D dataset in a deterministic option with periodic validation.
python tools/train.py configs/skeleton/stgcn/stgcn_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py \
--seed 0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test STGCN model on NTU60-2D dataset and dump the result to a pickle file.
python tools/test.py configs/skeleton/stgcn/stgcn_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@inproceedings{yan2018spatial,
title={Spatial temporal graph convolutional networks for skeleton-based action recognition},
author={Yan, Sijie and Xiong, Yuanjun and Lin, Dahua},
booktitle={Thirty-second AAAI conference on artificial intelligence},
year={2018}
}
STGCN++¶
PYSKL: Towards Good Practices for Skeleton Action Recognition
Abstract¶
We present PYSKL: an open-source toolbox for skeleton-based action recognition based on PyTorch. The toolbox supports a wide variety of skeleton action recognition algorithms, including approaches based on GCN and CNN. In contrast to existing open-source skeleton action recognition projects that include only one or two algorithms, PYSKL implements six different algorithms under a unified framework with both the latest and original good practices to ease the comparison of efficacy and efficiency. We also provide an original GCN-based skeleton action recognition model named ST-GCN++, which achieves competitive recognition performance without any complicated attention schemes, serving as a strong baseline. Meanwhile, PYSKL supports the training and testing of nine skeleton-based action recognition benchmarks and achieves state-of-the-art recognition performance on eight of them. To facilitate future research on skeleton action recognition, we also provide a large number of trained models and detailed benchmark results to give some insights. PYSKL is released at this https URL and is actively maintained. We will update this report when we add new features or benchmarks. The current version corresponds to PYSKL v0.2.
Results and Models¶
NTU60_XSub_2D¶
| frame sampling strategy | modality | gpus | backbone | top1 acc | testing protocol | FLOPs | params | config | ckpt | log |
|---|---|---|---|---|---|---|---|---|---|---|
| uniform 100 | joint | 8 | STGCN++ | 89.29 | 10 clips | 1.95G | 1.39M | config | ckpt | log |
| uniform 100 | bone | 8 | STGCN++ | 92.30 | 10 clips | 1.95G | 1.39M | config | ckpt | log |
| uniform 100 | joint-motion | 8 | STGCN++ | 87.30 | 10 clips | 1.95G | 1.39M | config | ckpt | log |
| uniform 100 | bone-motion | 8 | STGCN++ | 88.76 | 10 clips | 1.95G | 1.39M | config | ckpt | log |
| two-stream | 92.61 | |||||||||
| four-stream | 92.77 |
NTU60_XSub_3D¶
| frame sampling strategy | modality | gpus | backbone | top1 acc | testing protocol | FLOPs | params | config | ckpt | log |
|---|---|---|---|---|---|---|---|---|---|---|
| uniform 100 | joint | 8 | STGCN++ | 89.14 | 10 clips | 2.96G | 1.4M | config | ckpt | log |
| uniform 100 | bone | 8 | STGCN++ | 90.21 | 10 clips | 2.96G | 1.4M | config | ckpt | log |
| uniform 100 | joint-motion | 8 | STGCN++ | 86.67 | 10 clips | 2.96G | 1.4M | config | ckpt | log |
| uniform 100 | bone-motion | 8 | STGCN++ | 87.45 | 10 clips | 2.96G | 1.4M | config | ckpt | log |
| two-stream | 91.39 | |||||||||
| four-stream | 91.87 |
The gpus indicates the number of gpus we used to get the checkpoint. If you want to use a different number of gpus or videos per gpu, the best way is to set
--auto-scale-lrwhen callingtools/train.py, this parameter will auto-scale the learning rate according to the actual batch size, and the original batch size.For two-stream fusion, we use joint : bone = 1 : 1. For four-stream fusion, we use joint : joint-motion : bone : bone-motion = 2 : 1 : 2 : 1. For more details about multi-stream fusion, please refer to this tutorial.
Train¶
You can use the following command to train a model.
python tools/train.py ${CONFIG_FILE} [optional arguments]
Example: train STGCN++ model on NTU60-2D dataset in a deterministic option with periodic validation.
python tools/train.py configs/skeleton/stgcnpp/stgcnpp_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py \
--seed 0 --deterministic
For more details, you can refer to the Training part in the Training and Test Tutorial.
Test¶
You can use the following command to test a model.
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [optional arguments]
Example: test STGCN++ model on NTU60-2D dataset and dump the result to a pickle file.
python tools/test.py configs/skeleton/stgcnpp/stgcnpp_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py \
checkpoints/SOME_CHECKPOINT.pth --dump result.pkl
For more details, you can refer to the Test part in the Training and Test Tutorial.
Citation¶
@misc{duan2022PYSKL,
url = {https://arxiv.org/abs/2205.09443},
author = {Duan, Haodong and Wang, Jiaqi and Chen, Kai and Lin, Dahua},
title = {PYSKL: Towards Good Practices for Skeleton Action Recognition},
publisher = {arXiv},
year = {2022}
}