Welcome to Projects of MMAction2¶
In this folder, we welcome all contributions of deep-learning video understanding models from the community.
Here, these requirements, e.g., code standards, are not as strict as in the core package. Thus, developers from the community can implement their algorithms much more easily and efficiently in MMAction2. We appreciate all contributions from the community to make MMAction2 greater.
Here is an example project about how to add your algorithms easily.
We also provide some documentation listed below:
-
The guides for new contributors about how to add your projects to MMAction2.
-
Welcome to start a discussion!
Example Project¶
This is an example README for community projects/. You can write your README in your own project. Here are
some recommended parts of a README for others to understand and use your project, you can copy or modify them
according to your project.
Usage¶
Setup Environment¶
Please refer to Get Started to install MMAction2.
At first, add the current folder to PYTHONPATH, so that Python can find your code. Run command in the current directory to add it.
Please run it every time after you opened a new shell.
export PYTHONPATH=`pwd`:$PYTHONPATH
Data Preparation¶
Prepare the Kinetics400 dataset according to the instruction.
Training commands¶
To train with single GPU:
mim train mmaction configs/examplenet_r50-in1k-pre_8xb32-1x1x3-100e_kinetics400-rgb.py
To train with multiple GPUs:
mim train mmaction configs/examplenet_r50-in1k-pre_8xb32-1x1x3-100e_kinetics400-rgb.py --launcher pytorch --gpus 8
To train with multiple GPUs by slurm:
mim train mmaction configs/examplenet_r50-in1k-pre_8xb32-1x1x3-100e_kinetics400-rgb.py --launcher slurm \
--gpus 8 --gpus-per-node 8 --partition $PARTITION
Testing commands¶
To test with single GPU:
mim test mmaction configs/examplenet_r50-in1k-pre_8xb32-1x1x3-100e_kinetics400-rgb.py --checkpoint $CHECKPOINT
To test with multiple GPUs:
mim test mmaction configs/examplenet_r50-in1k-pre_8xb32-1x1x3-100e_kinetics400-rgb.py --checkpoint $CHECKPOINT --launcher pytorch --gpus 8
To test with multiple GPUs by slurm:
mim test mmaction configs/examplenet_r50-in1k-pre_8xb32-1x1x3-100e_kinetics400-rgb.py --checkpoint $CHECKPOINT --launcher slurm \
--gpus 8 --gpus-per-node 8 --partition $PARTITION
Results¶
frame sampling strategy |
resolution |
gpus |
backbone |
pretrain |
top1 acc |
top5 acc |
testing protocol |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|---|---|
1x1x3 |
224x224 |
8 |
ResNet50 |
ImageNet |
72.83 |
90.65 |
25 clips x 10 crop |
Citation¶
@misc{2020mmaction2,
title={OpenMMLab's Next Generation Video Understanding Toolbox and Benchmark},
author={MMAction2 Contributors},
howpublished = {\url{https://github.com/open-mmlab/mmaction2}},
year={2020}
}
Checklist¶
Here is a checklist of this project’s progress, and you can ignore this part if you don’t plan to contribute to MMAction2 projects.
[ ] Milestone 1: PR-ready, and acceptable to be one of the
projects/.[ ] Finish the code
[ ] Basic docstrings & proper citation
[ ] Converted checkpoint and results (Only for reproduction)
[ ] Milestone 2: Indicates a successful model implementation.
[ ] Training results
[ ] Milestone 3: Good to be a part of our core package!
[ ] Unit tests
[ ] Code style
[ ]
metafile.ymlandREADME.md
Gesture Recognition¶
Introduction¶
In this project, we present a skeleton based pipeline for gesture recognition. The pipeline is three-stage. The first stage consists of a hand detection module that outputs bounding boxes of human hands from video frames. Afterwards, the second stage employs a pose estimation module to generate keypoints of the detected hands. Finally, the third stage utilizes a skeleton-based gesture recognition module to classify hand actions based on the provided hand skeleton. The three-stage pipeline is lightweight and can achieve real-time on CPU devices. In this README, we provide the models and the inference demo for the project. Training data preparation and training scripts are described in TRAINING.md.
Hand detection stage¶
Hand detection results on OneHand10K validation dataset
Config |
Input Size |
bbox mAP |
bbox mAP 50 |
bbox mAP 75 |
ckpt |
log |
|---|---|---|---|---|---|---|
320x320 |
0.8100 |
0.9870 |
0.9190 |
Pose estimation stage¶
Pose estimation results on COCO-WholeBody-Hand validation set
Config |
Input Size |
PCK@0.2 |
AUC |
EPE |
ckpt |
|---|---|---|---|---|---|
256x256 |
0.815 |
0.837 |
4.51 |
Gesture recognition stage¶
Skeleton base gesture recognition results on Jester validation
Config |
Input Size |
Top 1 accuracy |
Top 5 accuracy |
ckpt |
log |
|---|---|---|---|---|---|
100x17x3 |
89.22 |
97.52 |
CTRGCN Project¶
Channel-wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition
Abstract¶
Graph convolutional networks (GCNs) have been widely used and achieved remarkable results in skeleton-based action recognition. In GCNs, graph topology dominates feature aggregation and therefore is the key to extracting representative features. In this work, we propose a novel Channel-wise Topology Refinement Graph Convolution (CTR-GC) to dynamically learn different topologies and effectively aggregate joint features in different channels for skeleton-based action recognition. The proposed CTR-GC models channel-wise topologies through learning a shared topology as a generic prior for all channels and refining it with channel-specific correlations for each channel. Our refinement method introduces few extra parameters and significantly reduces the difficulty of modeling channel-wise topologies. Furthermore, via reformulating graph convolutions into a unified form, we find that CTR-GC relaxes strict constraints of graph convolutions, leading to stronger representation capability. Combining CTR-GC with temporal modeling modules, we develop a powerful graph convolutional network named CTR-GCN which notably outperforms state-of-the-art methods on the NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets.

Usage¶
Setup Environment¶
Please refer to Installation to install MMAction2.
Assume that you are located at $MMACTION2/projects/ctrgcn.
Add the current folder to PYTHONPATH, so that Python can find your code. Run the following command in the current directory to add it.
Please run it every time after you opened a new shell.
export PYTHONPATH=`pwd`:$PYTHONPATH
Data Preparation¶
Prepare the NTU60 dataset according to the instruction.
Create a symbolic link from $MMACTION2/data to ./data in the current directory, so that Python can locate your data. Run the following command in the current directory to create the symbolic link.
ln -s ../../data ./data
Training commands¶
To train with single GPU:
mim train mmaction configs/ctrgcn_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py
To train with multiple GPUs:
mim train mmaction configs/ctrgcn_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py --launcher pytorch --gpus 8
To train with multiple GPUs by slurm:
mim train mmaction configs/ctrgcn_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py --launcher slurm \
--gpus 8 --gpus-per-node 8 --partition $PARTITION
Testing commands¶
To test with single GPU:
mim test mmaction configs/ctrgcn_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py --checkpoint $CHECKPOINT
To test with multiple GPUs:
mim test mmaction configs/ctrgcn_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py --checkpoint $CHECKPOINT --launcher pytorch --gpus 8
To test with multiple GPUs by slurm:
mim test mmaction configs/ctrgcn_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py --checkpoint $CHECKPOINT --launcher slurm \
--gpus 8 --gpus-per-node 8 --partition $PARTITION
Results¶
NTU60_XSub_2D¶
frame sampling strategy |
modality |
gpus |
backbone |
top1 acc |
testing protocol |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|
uniform 100 |
joint |
8 |
CTRGCN |
89.6 |
10 clips |
NTU60_XSub_3D¶
frame sampling strategy |
modality |
gpus |
backbone |
top1 acc |
testing protocol |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|
uniform 100 |
joint |
8 |
CTRGCN |
89.0 |
10 clips |
Citation¶
@inproceedings{chen2021channel,
title={Channel-wise topology refinement graph convolution for skeleton-based action recognition},
author={Chen, Yuxin and Zhang, Ziqi and Yuan, Chunfeng and Li, Bing and Deng, Ying and Hu, Weiming},
booktitle={CVPR},
pages={13359--13368},
year={2021}
}
ActionCLIP Project¶
ActionCLIP: A New Paradigm for Video Action Recognition
Abstract¶
The canonical approach to video action recognition dictates a neural model to do a classic and standard 1-of-N majority vote task. They are trained to predict a fixed set of predefined categories, limiting their transferable ability on new datasets with unseen concepts. In this paper, we provide a new perspective on action recognition by attaching importance to the semantic information of label texts rather than simply mapping them into numbers. Specifically, we model this task as a video-text matching problem within a multimodal learning framework, which strengthens the video representation with more semantic language supervision and enables our model to do zero-shot action recognition without any further labeled data or parameters requirements. Moreover, to handle the deficiency of label texts and make use of tremendous web data, we propose a new paradigm based on this multimodal learning framework for action recognition, which we dub “pre-train, prompt and fine-tune”. This paradigm first learns powerful representations from pre-training on a large amount of web image-text or video-text data. Then it makes the action recognition task to act more like pre-training problems via prompt engineering. Finally, it end-to-end fine-tunes on target datasets to obtain strong performance. We give an instantiation of the new paradigm, ActionCLIP, which not only has superior and flexible zero-shot/few-shot transfer ability but also reaches a top performance on general action recognition task, achieving 83.8% top-1 accuracy on Kinetics-400 with a ViT-B/16 as the backbone.

Usage¶
Setup Environment¶
Please refer to Installation to install MMAction2. Run the following command to install clip.
pip install git+https://github.com/openai/CLIP.git
Assume that you are located at $MMACTION2/projects/actionclip.
Add the current folder to PYTHONPATH, so that Python can find your code. Run the following command in the current directory to add it.
Please run it every time after you opened a new shell.
export PYTHONPATH=`pwd`:$PYTHONPATH
Data Preparation¶
Prepare the Kinetics400 dataset according to the instruction.
Create a symbolic link from $MMACTION2/data to ./data in the current directory, so that Python can locate your data. Run the following command in the current directory to create the symbolic link.
ln -s ../../data ./data
Training commands¶
To train with single GPU:
mim train mmaction configs/actionclip_vit-base-p32-res224-clip-pre_g8xb16_1x1x8_k400-rgb.py
To train with multiple GPUs:
mim train mmaction configs/actionclip_vit-base-p32-res224-clip-pre_g8xb16_1x1x8_k400-rgb.py --launcher pytorch --gpus 8
To train with multiple GPUs by slurm:
mim train mmaction configs/actionclip_vit-base-p32-res224-clip-pre_g8xb16_1x1x8_k400-rgb.py --launcher slurm \
--gpus 8 --gpus-per-node 8 --partition $PARTITION
Testing commands¶
To test with single GPU:
mim test mmaction configs/actionclip_vit-base-p32-res224-clip-pre_g8xb16_1x1x8_k400-rgb.py --checkpoint $CHECKPOINT
To test with multiple GPUs:
mim test mmaction configs/actionclip_vit-base-p32-res224-clip-pre_g8xb16_1x1x8_k400-rgb.py --checkpoint $CHECKPOINT --launcher pytorch --gpus 8
To test with multiple GPUs by slurm:
mim test mmaction configs/actionclip_vit-base-p32-res224-clip-pre_g8xb16_1x1x8_k400-rgb.py --checkpoint $CHECKPOINT --launcher slurm \
--gpus 8 --gpus-per-node 8 --partition $PARTITION
Results¶
Kinetics400¶
frame sampling strategy |
backbone |
top1 acc |
top5 acc |
testing protocol |
config |
ckpt |
|---|---|---|---|---|---|---|
1x1x8 |
ViT-B/32 |
77.6 |
93.8 |
8 clips x 1 crop |
ckpt[1] |
|
1x1x8 |
ViT-B/16 |
80.3 |
95.2 |
8 clips x 1 crop |
ckpt[1] |
|
1x1x16 |
ViT-B/16 |
81.1 |
95.6 |
16 clips x 1 crop |
ckpt[1] |
|
1x1x32 |
ViT-B/16 |
81.3 |
95.8 |
32 clips x 1 crop |
ckpt[1] |
[1] The models are ported from the repo ActionCLIP and tested on our data. Currently, we only support the testing of ActionCLIP models. Due to the variation in testing data, our reported test accuracy differs from that of the original repository (on average, it is lower by one point). Please refer to this issue for more details.
Kinetics400 (Trained on Our K400 dataset)¶
frame sampling strategy |
gpus |
backbone |
top1 acc |
top5 acc |
testing protocol |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|
1x1x8 |
8 |
ViT-B/32 |
77.5 |
93.2 |
8 clips x 1 crop |
|||
1x1x8 |
8 |
ViT-B/16 |
81.3 |
95.2 |
8 clips x 1 crop |
Zero-Shot Prediction¶
We offer two methods for zero-shot prediction as follows. The test.mp4 can be downloaded from here.
Using Naive Pytorch¶
import torch
import clip
from models.load import init_actionclip
from mmaction.utils import register_all_modules
register_all_modules(True)
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = init_actionclip('ViT-B/32-8', device=device)
video_anno = dict(filename='test.mp4', start_index=0)
video = preprocess(video_anno).unsqueeze(0).to(device)
template = 'The woman is {}'
labels = ['singing', 'dancing', 'performing']
text = clip.tokenize([template.format(label) for label in labels]).to(device)
with torch.no_grad():
video_features = model.encode_video(video)
text_features = model.encode_text(text)
video_features /= video_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100 * video_features @ text_features.T).softmax(dim=-1)
probs = similarity.cpu().numpy()
print("Label probs:", probs) # [[9.995e-01 5.364e-07 6.666e-04]]
Using MMAction2 APIs¶
import mmengine
import torch
from mmaction.utils import register_all_modules
from mmaction.apis import inference_recognizer, init_recognizer
register_all_modules(True)
config_path = 'configs/actionclip_vit-base-p32-res224-clip-pre_1x1x8_k400-rgb.py'
checkpoint_path = 'https://download.openmmlab.com/mmaction/v1.0/projects/actionclip/actionclip_vit-base-p32-res224-clip-pre_1x1x8_k400-rgb/vit-b-32-8f.pth'
template = 'The woman is {}'
labels = ['singing', 'dancing', 'performing']
# Update the labels, the default is the label list of K400.
config = mmengine.Config.fromfile(config_path)
config.model.labels_or_label_file = labels
config.model.template = template
device = "cuda" if torch.cuda.is_available() else "cpu"
model = init_recognizer(config=config, checkpoint=checkpoint_path, device=device)
pred_result = inference_recognizer(model, 'test.mp4')
probs = pred_result.pred_score.cpu().numpy()
print("Label probs:", probs) # [9.995e-01 5.364e-07 6.666e-04]
Citation¶
@article{wang2021actionclip,
title={Actionclip: A new paradigm for video action recognition},
author={Wang, Mengmeng and Xing, Jiazheng and Liu, Yong},
journal={arXiv preprint arXiv:2109.08472},
year={2021}
}
Knowledge Distillation Based on MMRazor¶
Knowledge Distillation is a classic model compression method. The core idea is to “imitate” a teacher model (or multi-model ensemble) with better performance and more complex structure by guiding a lightweight student model, improving the performance of the student model without changing its structure. MMRazor is a model compression toolkit for model slimming and AutoML, which supports several KD algorithms. In this project, we take TSM-MobileNetV2 as an example to show how to use MMRazor to perform knowledge distillation on action recognition models. You could refer to more MMRazor for more model compression algorithms.
Description¶
This is an implementation of MMRazor Knowledge Distillation Application, we provide action recognition configs and models for MMRazor.
Usage¶
Prerequisites¶
MMRazor v1.0.0 or higher
There are two install modes:
Option (a). Install as a Python package
mim install "mmrazor>=1.0.0"
Option (b). Install from source
git clone https://github.com/open-mmlab/mmrazor.git
cd mmrazor
pip install -v -e .
Setup Environment¶
Please refer to Get Started to install MMAction2.
At first, add the current folder to PYTHONPATH, so that Python can find your code. Run command in the current directory to add it.
Please run it every time after you opened a new shell.
export PYTHONPATH=`pwd`:$PYTHONPATH
Data Preparation¶
Data Preparation¶
Prepare the Kinetics400 dataset according to the instruction.
Create a symbolic link from $MMACTION2/data to ./data in the current directory, so that Python can locate your data. Run the following command in the current directory to create the symbolic link.
ln -s ../../data ./data
Training commands¶
To train with single GPU:
mim train mmrazor configs/kd_logits_tsm-res50_tsm-mobilenetv2_8xb16_k400.py
To train with multiple GPUs:
mim train mmrazor configs/kd_logits_tsm-res50_tsm-mobilenetv2_8xb16_k400.py --launcher pytorch --gpus 8
To train with multiple GPUs by slurm:
mim train mmrazor configs/kd_logits_tsm-res50_tsm-mobilenetv2_8xb16_k400.py --launcher slurm \
--gpus 8 --gpus-per-node 8 --partition $PARTITION
Testing commands¶
Please convert the knowledge distillation checkpoint to student-only checkpoint with following commands, you will get a checkpoint with a ‘_student.pth’ suffix under the same directory as the original checkpoint. Then take the student-only checkpoint for testing.
mim run mmrazor convert_kd_ckpt_to_student $CHECKPOINT
To test with single GPU:
mim test mmaction tsm_imagenet-pretrained-mobilenetv2_8xb16-1x1x8-100e_kinetics400-rgb.py --checkpoint $CHECKPOINT
To test with multiple GPUs:
mim test mmaction tsm_imagenet-pretrained-mobilenetv2_8xb16-1x1x8-100e_kinetics400-rgb.py --checkpoint $CHECKPOINT --launcher pytorch --gpus 8
To test with multiple GPUs by slurm:
mim test mmaction tsm_imagenet-pretrained-mobilenetv2_8xb16-1x1x8-100e_kinetics400-rgb.py --checkpoint $CHECKPOINT --launcher slurm \
--gpus 8 --gpus-per-node 8 --partition $PARTITION
Results and models¶
Location |
Dataset |
Teacher |
Student |
Acc |
Acc(T) |
Acc(S) |
Config |
Download |
|---|---|---|---|---|---|---|---|---|
logits |
Kinetics-400 |
69.60(+0.9) |
73.22 |
68.71 |
||||
logits |
Kinetics-400 |
75.54(+1.4) |
79.22 |
74.12 |
Citation¶
@article{huang2022knowledge,
title={Knowledge Distillation from A Stronger Teacher},
author={Huang, Tao and You, Shan and Wang, Fei and Qian, Chen and Xu, Chang},
journal={arXiv preprint arXiv:2205.10536},
year={2022}
}
UMT Project¶
Unmasked Teacher: Towards Training-Efficient Video Foundation Models
Abstract¶
Video Foundation Models (VFMs) have received limited exploration due to high computational costs and data scarcity. Previous VFMs rely on Image Foundation Models (IFMs), which face challenges in transferring to the video domain. Although VideoMAE has trained a robust ViT from limited data, its low-level reconstruction poses convergence difficulties and conflicts with high-level cross-modal alignment. This paper proposes a training-efficient method for temporal-sensitive VFMs that integrates the benefits of existing methods. To increase data efficiency, we mask out most of the low-semantics video tokens, but selectively align the unmasked tokens with IFM, which serves as the UnMasked Teacher (UMT). By providing semantic guidance, our method enables faster convergence and multimodal friendliness. With a progressive pre-training framework, our model can handle various tasks including scene-related, temporal-related, and complex video-language understanding. Using only public sources for pre-training in 6 days on 32 A100 GPUs, our scratch-built ViT-L/16 achieves state-of-the-art performances on various video tasks.
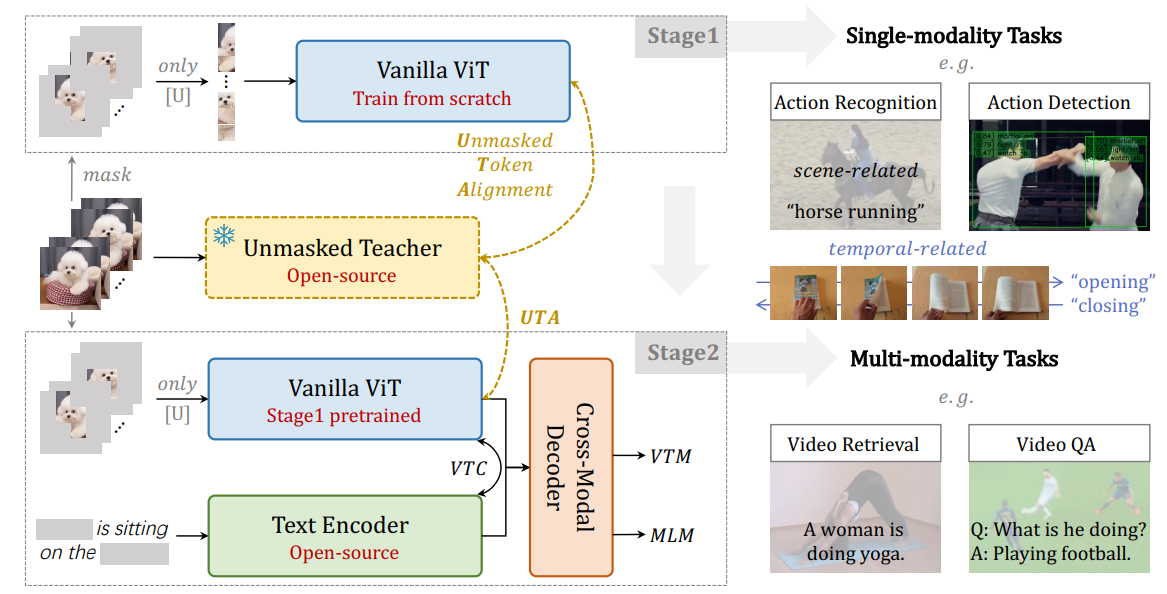
Usage¶
Setup Environment¶
Please refer to Installation to install MMAction2.
Assume that you are located at $MMACTION2/projects/umt.
Add the current folder to PYTHONPATH, so that Python can find your code. Run the following command in the current directory to add it.
Please run it every time after you opened a new shell.
export PYTHONPATH=`pwd`:$PYTHONPATH
Data Preparation¶
Prepare the Kinetics dataset according to the instruction.
Create a symbolic link from $MMACTION2/data to ./data in the current directory, so that Python can locate your data. Run the following command in the current directory to create the symbolic link.
ln -s ../../data ./data
Testing commands¶
To test with single GPU:
mim test mmaction configs/umt-base-p16-res224_kinetics710-pre-ft_u8_k400-rgb.py --checkpoint $CHECKPOINT
To test with multiple GPUs:
mim test mmaction configs/umt-base-p16-res224_kinetics710-pre-ft_u8_k400-rgb.py --checkpoint $CHECKPOINT --launcher pytorch --gpus 8
To test with multiple GPUs by slurm:
mim test mmaction configs/umt-base-p16-res224_kinetics710-pre-ft_u8_k400-rgb.py --checkpoint $CHECKPOINT --launcher slurm \
--gpus 8 --gpus-per-node 8 --partition $PARTITION
Results¶
Kinetics400¶
frame sampling strategy |
resolution |
backbone |
pretrain |
top1 acc |
testing protocol |
config |
ckpt |
|---|---|---|---|---|---|---|---|
uniform 8 |
224x224 |
UMT-B |
Kinetics710 |
87.33 |
4 clips x 3 crop |
||
uniform 8 |
224x224 |
UMT-L |
Kinetics710 |
90.21 |
4 clips x 3 crop |
Kinetics700¶
frame sampling strategy |
resolution |
backbone |
pretrain |
top1 acc |
testing protocol |
config |
ckpt |
|---|---|---|---|---|---|---|---|
uniform 8 |
224x224 |
UMT-B |
Kinetics710 |
77.95 |
4 clips x 3 crop |
||
uniform 8 |
224x224 |
UMT-L |
Kinetics710 |
82.79 |
4 clips x 3 crop |
Citation¶
@article{li2023unmasked,
title={Unmasked teacher: Towards training-efficient video foundation models},
author={Li, Kunchang and Wang, Yali and Li, Yizhuo and Wang, Yi and He, Yinan and Wang, Limin and Qiao, Yu},
journal={arXiv preprint arXiv:2303.16058},
year={2023}
}
MSG3D Project¶
Disentangling and Unifying Graph Convolutions for Skeleton-Based Action Recognition
Abstract¶
Spatial-temporal graphs have been widely used by skeleton-based action recognition algorithms to model human action dynamics. To capture robust movement patterns from these graphs, long-range and multi-scale context aggregation and spatial-temporal dependency modeling are critical aspects of a powerful feature extractor. However, existing methods have limitations in achieving (1) unbiased long-range joint relationship modeling under multi-scale operators and (2) unobstructed cross-spacetime information flow for capturing complex spatial-temporal dependencies. In this work, we present (1) a simple method to disentangle multi-scale graph convolutions and (2) a unified spatial-temporal graph convolutional operator named G3D. The proposed multi-scale aggregation scheme disentangles the importance of nodes in different neighborhoods for effective long-range modeling. The proposed G3D module leverages dense cross-spacetime edges as skip connections for direct information propagation across the spatial-temporal graph. By coupling these proposals, we develop a powerful feature extractor named MS-G3D based on which our model outperforms previous state-of-the-art methods on three large-scale datasets: NTU RGB+D 60, NTU RGB+D 120, and Kinetics Skeleton 400.

Usage¶
Setup Environment¶
Please refer to Installation to install MMAction2.
Assume that you are located at $MMACTION2/projects/msg3d.
Add the current folder to PYTHONPATH, so that Python can find your code. Run the following command in the current directory to add it.
Please run it every time after you opened a new shell.
export PYTHONPATH=`pwd`:$PYTHONPATH
Data Preparation¶
Prepare the NTU60 dataset according to the instruction.
Create a symbolic link from $MMACTION2/data to ./data in the current directory, so that Python can locate your data. Run the following command in the current directory to create the symbolic link.
ln -s ../../data ./data
Data Preparation¶
Prepare the NTU60 dataset according to the instruction.
Training commands¶
To train with single GPU:
mim train mmaction configs/msg3d_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py
To train with multiple GPUs:
mim train mmaction configs/msg3d_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py --launcher pytorch --gpus 8
To train with multiple GPUs by slurm:
mim train mmaction configs/msg3d_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py --launcher slurm \
--gpus 8 --gpus-per-node 8 --partition $PARTITION
Testing commands¶
To test with single GPU:
mim test mmaction configs/msg3d_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py --checkpoint $CHECKPOINT
To test with multiple GPUs:
mim test mmaction configs/msg3d_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py --checkpoint $CHECKPOINT --launcher pytorch --gpus 8
To test with multiple GPUs by slurm:
mim test mmaction configs/msg3d_8xb16-joint-u100-80e_ntu60-xsub-keypoint-2d.py --checkpoint $CHECKPOINT --launcher slurm \
--gpus 8 --gpus-per-node 8 --partition $PARTITION
Results¶
NTU60_XSub_2D¶
frame sampling strategy |
modality |
gpus |
backbone |
top1 acc |
testing protocol |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|
uniform 100 |
joint |
8 |
MSG3D |
92.3 |
10 clips |
NTU60_XSub_3D¶
frame sampling strategy |
modality |
gpus |
backbone |
top1 acc |
testing protocol |
config |
ckpt |
log |
|---|---|---|---|---|---|---|---|---|
uniform 100 |
joint |
8 |
MSG3D |
89.6 |
10 clips |
Citation¶
@inproceedings{liu2020disentangling,
title={Disentangling and unifying graph convolutions for skeleton-based action recognition},
author={Liu, Ziyu and Zhang, Hongwen and Chen, Zhenghao and Wang, Zhiyong and Ouyang, Wanli},
booktitle={CVPR},
pages={143--152},
year={2020}
}